
人工知能が直面している最も重要な課題の 1 つはプライバシーです。 AI、特に機械学習には驚くべき変化の可能性があり、優れたトレーニング済みモデルを使用すれば、少し前までは考えられなかった機能をデバイスで実行できることを私たちは知っています。
機械学習により、iPhone は Face ID で私たちを認識し、私たちの顔が日々どのように変化するかを学習できるようになります。これにより、内容に基づいて特定の写真を検索して見つけることができます (何年も前に息子が大好きなスーパーマンの T シャツを着て撮った写真です)。また、音を認識したり、最も適切な場所に沿ってガイドしたりすることもできます。渋滞を避けて効率的に帰宅できるルート。彼は一人で車を運転して私たちを目的地まで連れて行ってくれることさえできます。
そして、これはまだ遊び始めたばかりです。間もなく、人間の医師よりも優れた効率レベルで、検査を簡単に分析するだけで、あらゆる病気の可能性を診断できるようになるでしょう。重要なことは、機械学習が私たちに何をしてくれるかということではありません。それは私には想像できないことですが、必ず起こります。これらすべての根拠は何でしょうか?データ。データとさらなるデータ。
データとプライバシー
データがなければ、機械学習は役に立たないでしょう。機械学習モデルはトレーニングする必要があり、そのトレーニングはデータに基づいているためです。マーベルのスーパーヒーローが誰であるかを私が説明しなければ、私のカメラでスーパーヒーローの写真を撮っても、ほとんどそれが分からないでしょう。そして、自分自身を訓練するために使用したそれぞれの画像の数が増えるほど、仕事を実行し、それらを識別するためのより効率的なパターンを見つけることができます。これは基本的なことです。

そして誰がデータを生成するのでしょうか?私たち。 3 つの基本的な焦点から:
- テクノロジーとのやり取りによって生成されるユーザー データ(写真、ドキュメント、ナビゲーション、位置情報など)。
- 機関や企業によって開発された研究であり、健康、人口、政治的傾向の研究など、特定のテーマに関するより組織化された世界的なデータを当社からも入手しています。
- 上記すべての結果として、企業や機関が何百万人もの人々から収集した大規模な外部データのセットが存在します。 Netflix がユーザーの好みについて持っているデータや、Google や Facebook が世界人口の大多数の生活習慣や購買習慣について持っているデータと同様です。
通常の手順では、このデータは何らかの方法で分類され、すでに定義されているモデルに渡されてトレーニングされます。
Google や Apple が私の写真を使って画像認識および分類モデルをトレーニングしている場合、誰かがそれらのモデルから私の写真を抽出することは可能でしょうか?誰かが私が何を作ったか知っていますか?たとえば、大都市での移動プロファイルを作成するために AI にデータが入力された場合、AI は私自身のプライバシーを危険にさらすことになり、私の住んでいる場所や勤務先に関するデータが飛び交うことになるでしょうか?必要な予防策が講じられていない場合でも、このような事態が発生する可能性があります。

たとえば、私たちは立ち止まって、自分のいる場所から得られるあらゆるものについて考えたことがありますか?住んでいる場所や働いている場所だけでなく、
- あなたが健康な人かどうかは関係ありません。土曜日にパドルテニスコートのあるスポーツセンターで数時間過ごしたり、ランニングアプリで運動量を監視しながら毎日同じエリアを定期的にランニングしたりしていますか。
- はい、日曜日には近所の教会に1時間立ち寄るので、私たちはカトリック教徒を練習しています。
- 私たちがいつも洋服を買う場所。
- 私たちが好きな映画(あなたの映画の好みを調べるために Google アカウントへの確認メールと照合します)。
- 私たちが最もよく知っているスーパーマーケットはどれでしょうか?
- オフィスで通常よりも長い時間を過ごした場合。
- 私たちに恋人がいるとしたら(そしてそれは誰なのか)、私たちは x 日ごとに小さなホテルに数時間滞在します(「ステルスパートナー」の携帯電話のように)。
これらすべては場所だけで可能です。
携帯電話に Vips アプリをインストールせず、現金で支払わなかった親戚のように、そこで食事をした数時間後に携帯電話に、今回の訪問が気に入ったかどうかを尋ねるメールを受け取ったのです。彼らはどうやってそれを行うのでしょうか?ある日、地元の無料 Wi-Fi を使用し、別の Wi-Fi が近づくと、携帯電話が自動的に接続し、その信号を約 1 時間使用したことをシステムが認識する可能性があります。あるいは、Google アプリがこの位置情報アクティビティを記録し、そのデータを会社に転送し、そのデータが Vips グループに販売される可能性もあります。そして、はい、彼女は否定していますが、読んでいない利用規約に同意することで彼に許可を与えました。
今日の機械学習の仕組み
機械学習に取り組む企業の哲学は、クラウド上のマシンは機械学習における非常に重要なタスクに対してはるかに高い能力を備えているため、データを送信してもらい、すでに処理されているという言い訳をしています。

操作は明確です。トレーニング済みモデルを備えたアプリまたはシステムがあります。私はそれを使用しており、あらゆる種類の使用状況データを収集します。かなりの数 (各アプリによって異なりますが、データごとのデータ) が蓄積されると、それらはクラウドに送信され、そこで私たちのような他の何百万ものデータと処理され、モデルが改善 (再トレーニング) されます。より高い効率を実現します。将来のアップデートでは、デバイスのモデルが改良されたモデルに変更されます。
あるいは、それさえないかもしれません。安価な携帯電話や古い携帯電話を使用していて、そのプロセッサーの性能が十分ではない場合、パフォーマンスが低下するため、機械学習プロセスを喜んで実行することはできません。したがって、私たちはすべてをクラウドで行います。データを取得してクラウドに送信し、そこで処理されて応答が送信されます。データはどこにでも飛び交います。場合によっては、このプロセスを通じてデータが送信され、データがそこに到達したら、すべては信頼の問題になるからです。

Google や Facebook がプライバシーについて話し始めたのはここ数カ月のことです。しかし、それは興味深い概念、つまり彼らが私たちのデータをどのように扱うかについての情報から理解されています。彼らは、プライバシーとは私たちのデータを尊重するものではなく、データをどう扱うのかを私たちに知らせるだけだと考えています。これは、非常に多くの頭痛の種を引き起こした有名な GDPR が規定したものです。ユーザーによる一連の情報管理メカニズムを組み込み、企業がデータをどのように扱うのか、どのデータを使用するのか、誰にデータを転送するのかを明確に伝えるよう強制します。すべてがクリアでクリスタルです。
彼らのほとんどはそれを完璧にこなします(彼らの方が優れています)。問題は、それが私たちには関係ないことです。私たちはこの情報を読みません。しかし、「あなたのプライバシーは私たちにとって重要です」というメッセージと、私たちが探している記事を読もうと思わず押してしまう巨大な「はい、同意します」ボタンを、ぜひ一度読んでみてください。ある日、「詳細情報」をクリックして、どのようなデータが収集され、何社がそのデータを提供するのかを読んでください。おそらく、インターネットの閲覧とデータのプライバシーについて、異なる視点で見ているのかもしれません。
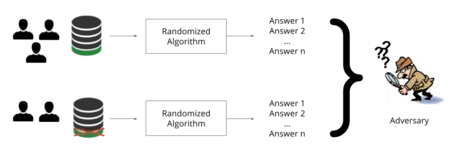
ここで Apple が機械学習プロセスの効率を損なうことなく貢献したいのは、データが有用であるように隠すことで使用されるデータのプライバシーを尊重することですが、そのデータが誰から来たのか、あるいはそのデータさえも決して分からないようにすることです。自身を使用:処理された結果のみが保存されます。そして、処理されたデータでは、元のデータとその生成者に到達することはできません。
iOS 13 の機械学習とプライバシー
iOS 13 以降では、モデルを改善するためにユーザー データを収集する場合、モデルが再トレーニングされ、データが制御不能に空間を「飛び回る」ように、データをクラウドに送信する必要がなくなりました。インターネット接続を必要とせずに、デバイス上でプロセス全体を実行できます。これを実現するために、Apple は 2 つの新しい API を有効にしました。1 つはデバイス上でモデルを再トレーニングできるようにするもので、もう 1 つは、いわゆる「長時間」のバックグラウンド プロセスを可能にするものです。このようにして、再トレーニングをスケジュールし、夜間にデバイスが充電されている間にモデルが再トレーニングされ、次回アプリを開いたときにすべての改善された機能を使用できるようになります。これは FaceID がすでに行っていることであり、現在すべての開発者に提供されています。
複数のユーザーのエクスペリエンスを追加したい場合はどうすればよいでしょうか?なぜなら、最初に生じる疑問は、改善されたトレーニング済みモデルがデバイス上にのみある場合、一般的なモデルにどのように貢献できるのかということだからです。わかりやすい例、Siri を見てみましょう。 iOS 13 以降、この再トレーニング機能がデバイス内で、デバイスから離れることなくユーザー エクスペリエンスに適用されるため、使用するにつれてさらに興味深い改善が見られます。
しかし、サービスを改善するために経験や Siri が学んだことを使いたい場合はどうすればよいでしょうか?開発者として、将来のバージョンで一般的なモデルを改善するために多くのユーザーの経験を活用したい場合はどうすればよいでしょうか?プライバシーを尊重しながら行うことができますか?
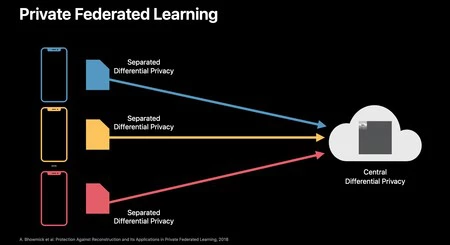
はい、 Apple がプライベート フェデレーション ラーニングと呼ばれる技術の適用を開始するためです。 2 つの重要な部分からなるテクニック。 1 つ目は、クラウドに送信されるのはデータではなく、改良されたモデルになるということです。 2 つ目は、すべてのデータに、すでに適用されている差分プライバシー制御が適用されることです。
このようにして、個別に再トレーニングされ改善されたモデルをすべて復元でき、改善された部分を含むそれらすべての融合が (データにアクセスする必要なく) 作成されます。そして、これを適用することで、個人データ、さらには画像コンテンツや機密情報が取得できる可能性のあるデータさえも難読化および非表示にする差分プライバシーがすでに確立されているため、他のユーザーから取得したデータを使用して新しいモデルでアプリを更新するときに、これらはいずれも入手できません。
システムの改善を可能にする技術の組み合わせですが、情報のプライバシーの尊重という非常に明確な点を常に念頭に置いています。機械学習の世界にはすでに存在しており、Apple がすべてのユーザーのプライバシーを保護するために適用することを決定した技術。プライバシーへの傾向を私たちに信じてもらいたい場合、他の企業もやるべきことです。
Apple がプレゼンテーションの 1 つで述べたように、プライバシーはすべてへの扉を閉ざすものではありません。それは、私たちがそれを開けるときは、私生活を尊重してくれる信頼できる人に開けるという安心感があることを意味します。